

前言
相信经常混 V 圈的小伙伴们一定听说过 Neuro-sama,她是一名完全由 AI 驱动的虚拟 Vtuber,在全国都有很高的知名度,那么Neuro-Sama是怎么实现的呢,想拥有一个属于自己的Neuro-Sama吗,在本文,我会分析Neuro是怎么构成的,并解析她究竟使用了哪些技术
作者在此提供了自己的思路,毕竟 Vedal(开发者)的开发技术是独一档的,而且Vedal本人并未公开完整代码,Github上面所有的开源方案都做不出他的效果,现有方案都是基于观察的逆向工程,笔者同样只能复现出最为基本的功能,效果肯定和Neuro-Sama比起来差很多
Neuro-Sama
如果遇到问题或者想指出文章的不足之处,欢迎评论留言或者给作者邮箱发消息哦
Neuro至本文截稿已经诞生3周年了,在此特祝 Neuro-sama 3周年快乐!
Neuro的基本原理
看过直播的都知道,在直播时,neuro能看见弹幕并互动,并且Vedal是直接通过说话来和Neuro进行交流的,说明了Neuro是采用了语音识别功能的,同时Neuro可以识别纯文本并给出回应
让我感到十分惊讶的是,Neuro甚至能玩MC和OSU!甚至在VRChat中一起贴贴!这个我们后面再讲
如图所示,以下是Neuro大致的运行流程(当然!事实上要复杂得多)

首先识别到语音,然后丢给语音识别模型,转换为语音文本,其次把语音文本丢给大模型,最后把大模型给出的文本转换为语音播放,就这样,你就得到了一个最基本的Ai聊天互动机器人
但是这个功能未必也太基础,太粗糙了,这个可承担不了Ai的大脑
要实现像Neuro一样智能的Ai,很多地方都需要优化,改良
Neuro-Sama的工作流程图如下,图片有点长,分为两部分展示
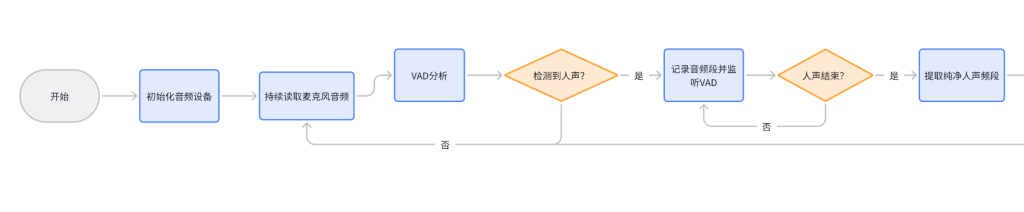

首先读取麦克风数据,然后VAD 采样分析并判断当前麦克风有没有人声输入(Voice activity detection,语音活性检测),如果检测到人声,就记录音频段并分析哪里是人声的开始和结束,提取出人声频段后,交给语音识别模型处理,并把文本提交给LLM(大模型)处理,根据提交的文本来生成回答的语句,如果检测到生成了完整的一句话,就把这句话扔给语音合成模型,得到音频数据,最后播放音频
以上就是一次与AI交流互动的完整流程
这里有个很有意思的小细节,为啥检测到完整的一句话就直接交给语音合成模型呢,而不是全部生成完毕后再提交
想一想,你说了一句话,语音识别模型花了1秒来给出文本,然后又花了2秒时间让LLM识别,最后语音合成又花了2秒,中间有足足5秒的时间得不到任何回应,用户的第一反应就是“哎,是不是卡了”,观感几乎为0,为了避免这种问题,该怎么办
简单提一嘴,Ai并不是一句话一句话生成的,而是每次生成一个字或者一个词,每次都重复判断下一个词/字最有可能是什么,这时,只要检测到生成了完整的一句话,就直接语音合成,也就是说,一边生成一边合成,也就是流式处理,这样用户从说话到收到回复的时间就大大缩短,观感++ :)
目前像千问这种类似的LLM貌似已经可以支持语音转语音的端到端输出了,读者可以自行了解,会省很多事的
总结:核心大体 STT -> LLM -> TTS
Live2D模型是怎么控制的
在直播时发现,Neuro的Live2D模型是可以根据语境来做出不同的动作和表情的,难道这个要像传统VTuber一样人为操控吗(也就是面捕),肯定不是的
一般来说,我们会提前给Ai设定好预设表情动作的参数,当LLM识别到开心,悲伤,愤怒等情绪时,就直接调用预设参数,来实现表情与动作的控制
这是让AI能拥有属于自己灵魂的方法,让模型的动作不再依赖于真人,而是由AI理解内容后自主决定,但是这个方案有点废token,经常用着用着钱包就被榨干了:(
第二种方案是语音驱动 (语音转口型/表情),这是目前最主流和最成熟的方案,AI分析输入的音频(语音)的频谱、音高、音量等信息,实时映射到Live2D模型的对应参数上,并控制嘴型的张开、闭合、嘴型变化,以及部分与发音相关的面部微表情,可以使用MMLive2D等插件来实现,这应该是最简单,也是最好实现的方法了,毕竟有现成的可以用
怎么让Ai玩游戏——加权求和
这个是令我感到最震撼的一点,Ai都能玩游戏了
Neuro-Sama现在可以游玩多款游戏,识别各种图片,这究竟是怎么做到的?
有一种不用接入大模型的方案
怎么让Ai玩游戏——VPT
让Ai玩游戏的另外一种思路是用视觉技术,模型微调,强化学习等方法给每个游戏量身定制一个模型,用于识别游戏中的内容,并给出回应
显而易见,这个方案关键是得自己搞模型,门槛太高、成本太大,学习成本也高:(
哎,我有一计,现在不是有很多现成的方案吗,我们不自己微调模型,只要每帧都截图,然后调用现成的多模态大模型来读图,生产语言再输入进LLM,就能让Ai拥有“视觉”,这不就方便了吗
但是在具体的实现中,我们会发现这样做延迟巨大,效果不好,观感相当差劲,每帧都截图也就说明每帧都要调用两个云端API,这种串行架构延迟能不高吗
[占位]
OpenAi曾经推出过一个基于纯视觉来游玩MC的模型,名字叫MineDojo,利用了VPT(视觉预训练)技术,这不是单纯预测像素,而是从海量的互联网视频(特别是包含人类与环境互动的视频,如游戏录像、教程视频) 中,学习人类行为的“模式”和“常识”,也就是通过观看视频学习行动,这就是VPT的本质
但是 MineDojo 不是单单只是VPT或者说是一个单一模型,而是一个完整的框架和平台,而VPT只是一种训练Ai的方法,读者不要搞混了
在传统的强化学习(RL)中,我们要训练一个用于玩MC的游戏AI,通常从一个随机参数开始,它通过“试错”获得奖励,慢慢学习,让AI从0开始自行摸索一切规则,效率极低,需要巨量的交互数据
但是我们已经知道了MC基本规则,我们知道 看到树要去砍、看到矿石要去挖、看到怪物要把他揍飞,每次开新档,并不是从零开始学习
这些游戏经验是哪来的呢,当然是通过自己的游玩体验和各种教学视频,游戏视频学来的,在2022年有人提出了想法(VPT),能不能让AI也通过这种“观看”的方式获得先验知识呢,于是,在传统RL的基础上产生了VPT技术
经过VPT预训练的模型,仅用少量强化学习微调,就能完成MC中一系列需要长期规划、复杂操作的顺序性任务(如砍树->制作工作台->制作木镐->挖石头->制作石制工具)
当它面对一棵树时,不再需要从零开始探索靠近、挥舞手臂等数百万种组合的可能结果;它的行为先验已经将其策略空间收敛到了 砍伐 、 躲避 或 忽略 等寥寥数个高概率选项上
经对VPT反复训练,我们就能得到一个简单的游戏特化模型,将海量游戏知识内化成一个本地、轻量的“条件反射”神经网络,直接从像素映射到动作,从而实现极低的延迟,做到看到树就能去砍,看到工作台就能合成,这就是目前已被验证且相对优秀的方案了
不过,也只是相对优秀而已,VPT只知道学习特定的知识,这样训练出来的模型数据是有偏见的,它的学习是被动的,没法让Ai拥有自己的灵魂,并且缺乏创造性,也就是说它无法处理游戏中未见过的突发情况
而且VPT这个模型训练方式成本相对偏高,调教出来的Ai性能取决于数据的质量与数量,就好比一个视频明明是讲做菜的,但是有很多运镜于做菜无关,用这种低质量视频训练,就会导致Ai学到的常识有偏差
OpenAi制作的MineDojo就是从 YouTube 收集了超过 70 万小时的MC相关视频,并附带了标题、描述、字幕等文本信息,还在wiki收集了MC的所有知识,很少有人有这样的精力去搞高质量且大量的素材
所有模仿学习的通病就是只知道模仿,不知道为什么这么做,比如Ai知道看到树要去砍,但是Ai不知道为啥要去砍树,它不会知道砍树是为了获得木头,木头可以合成工具
Ai的重点放在了事物的相关性上,而不是物理常识与因果逻辑,VPT这种训练范式在追求样本效率时,主动放弃了对因果机制建模所必须付出的代价
说白了,这就只是一个只会抄作业的学生,完全不知道举一反三,一点创造力都没有,那要这个模型有啥用
想一想,就只能用一个模型吗,我们完全可以一个大语言模型(LLM)专门负责生成对话,一个VPT调教的模型来控制游戏,把这俩模块搞成一个整体,不就有了Neuro的雏形了吗

评论(0)
暂无评论