

前言
本文介绍了模型微调最最基础的部分,目的是带读者体验简单微调的全过程,如果有一定基础请移步至提高篇
文章结构
- 第一部分,LLM微调的基本概念
- 1.1:大模型的本质是什么
- 1.2:怎么获得优质参数
- 1.3:什么是微调
- 1.4:什么时候该使用微调
- 1.5:怎么确定我微调的大模型学得好不好
- 1.6:微调的流程是什么
- 1.7:我需要使用哪些工具
- 第二部分,系统环境配置
- 2.1:安装CUDA
- 2.2:安装Ubuntu(可选)
- 2.3:安装LLaMA-Factory
- 2.3.1:安装LLaMA-Factory本体
- 2.3.2:配置虚拟环境
- 2.3.3:安装PyTorch
- 2.3:疑难杂症
- 第三部分,体验简单微调全过程
- 3.1:启动web界面
- 3.2:选择合适的模型
- 3.3:选择数据集
- 3.4:开始你的第一次微调吧!
第一部分,LLM微调的基本概念
大模型的本质是什么
一句话总结,模型的本质是函数,核心是参数,而训练是为了获得更好用的参数
大模型的地基是由Transformer这一自注意力机制神经网络架构组成,大模型每吐出一个词,都是根据当前的词计算下一个词的概率,而这个计算过程就是由函数完成的
函数里最重要的就是参数,参数决定模型算出来的结果准不准确,换而言之,模型的知识和能力都存储在参数里,模型智不智能,很重要的一点就是看参数好不好
所谓模型训练就是一个寻找优质参数的过程
怎么获得优质参数
大模型的参数与我们平时解方程不一样,没有固定的公式,而是一步一步计算出来的
计算过程是这样的:
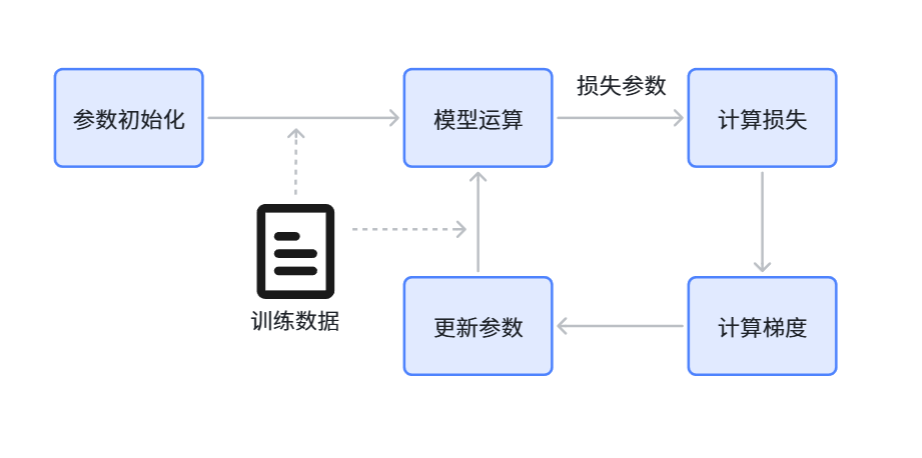
- 1.随机初始化参数
- 2.使用初始化的参数展开计算,也就是输入训练数据,模型预测下一个词的概率,比如下一个词是故事,但模型认为故事一词概率为0,这就错了,记录下这个错误,这个错误就叫损失
- 3.使用记录下来的损失参数进行求导,求导之后得到梯度(这个求导很复杂不用管)
- 4.根据梯度下降算法公式:新参数 = 旧参数 – 学习率 * 梯度 进行参数更新
- 5.用新参数再次输入训练数据,重复执行这个过程,对参数的值进行调整
这就是优化参数的全过程
什么是微调
模型微调是指在预训练模型的基础上,针对特定任务进行进一步训练的过程
预训练模型已经学习了大量通用语言知识,但在具体场景可能表现不佳
通过微调,我们可以让模型更好地理解和适应特定领域的语言特征和表达方式
简单来说,预训练的大模型就像一个马上参加高考的优秀学生,你给他一道高考数学题,他能很快给出答案,如果你给出一道数学奥赛的题,这时就有点力不从心了
这时,微调就像在做题之前对他进行辅导,使他成为一名MOer,再让他做奥赛题,效果就会好得多
总结:拿一个已经训练好的模型(预训练模型),在他的基础上继续训练,这就是微调
什么时候该使用微调
一般来说有两种情况,一是提示词不够用的时候,二是计算机资源不够用的时候,遇到这两种情况就可以烤炉微调了
1:什么是提示词不够用,就是在某些场景中,你竭尽所能的调整提示词,可模型输出结果还是不尽人意,比如Again工具调用,要让模型在用户提问中准确判断要使用哪个工具,纯靠提示词的话,需要高性能的模型,况且场景不能太复杂,再或者说是垂直领域提问,效果同样不好
2:什么是计算机资源不够,当提示词够用,但是要写的很长,要给出很多案例,和使用较大的模型,这时会有两个问题,一是资源消耗巨大,二是推理效果变慢
为了解决这两种问题,不只有微调这一解决方案,还有一种叫做RAG(检索生成强化)的方案,如果说微调是考试前给学生辅导,那么RAG就是给学生一本书让他考试时翻着看,简单来说就是外挂知识库,但是这不是本文的重点,简单了解即可
怎么确定我微调的大模型学得好不好
在反复的训练中,当我们觉得模型学会的时候,就可以停下来了,如果我们要知道多轮学习中模型学的怎么样了,最简单的方式就是监控前文提到的损失
如果损失没有下降,说明模型没学会,这种情况叫作过拟合,那就继续学,直到损失下降为止
损失函数掉了,不一定是学会了,就像学生上完课写作业,作业会写不代表知识学懂了,要通过考试才知道学没学会
我们准备另一份数据集,不能和用于训练的数据集重复,我们叫他验证集。把验证集丢给模型,如果训练集损失低,而验证集损失高,这个叫过拟合,说明模型学得不好,只是在照葫芦画瓢,没有真正理解。只有验证集和训练集损失同时下降,这才说明学的还不错
判断的指标远远不止这一个,之后会讲到
微调的流程是什么
微调概括来说有三个步骤,可以认为,微调就是基座模型+训练数据+微调方法
- 1:基座模型:要微调模型,肯定就得有个模型,选择的这个模型就是基座模型
- 2:训练数据:这是最最重要的一个环节,你准备的数据质量决定了模型的上限,花再多心思也不过分,业界有句话:你输入的是垃圾,得到的也是垃圾,一定要保证质量
- 3:微调方法:微调方法总结来看也分3种,LoRA微调,全局微调,冻结微调
- 1.全局微调:对所有参数进行调整,如果有10B参数,那就把10B参数全调整一遍
- 2.冻结微调:把底层的参数冻结起来,只调整靠近输入层的那几层
- 3.LoRA微调:不调整原来的参数,单独构建一个LoRA参数块,且只调整这一参数块,原参数 +LoRA参数块就得到的完整的参数,最推荐的微调方式,推荐初学者只用掌握这一种,只用调整少量数据即可达到很好的效果
我需要使用什么工具
本文给出两种方式部署并讲解,部分步骤需要科学上网,使用服务器跑模型和本地部署差不多,放到提高篇讲
本文采用LLaMA-Factory这个开源工具进行模型微调,自带web图形化界面,好用易上手
LLaMA-Factory前置:
- PyTorch:深度学习框架
- CUDA:NVIDIA GPU的并行计算平台,能让LLaMA-Factory调用GPU进行计算,单纯用CPU搞微调太慢了
- Python及相关库:需要Python环境来运行,推荐使用Python3.10版本
- NVIDIA驱动:无需多言
第二部分,系统环境配置
总所周知,搞Ai的百分之90的时间在配置环境,而写代码的时间只占了百分之10,遇到问题直接去看疑难杂症,还是无法解决可以自行询问大模型
安装CUDA
首先需要一张NVIDIA的并且支持CUDA的显卡,想知道自己的显卡能否支持,请自行询问大模型
打开NVIDIA官网,下载NVIDIA APP,安装后更新驱动到最新版本(安装过驱动就行)
在官网搜索CUDA并安装,这里推荐安装CUDA13.0
自行下载:
https://developer.nvidia.com/cuda-toolkit-archive
安装Ubuntu(可选)
对于本地部署,有两种方案,分别是:
1.Windows本地部署:直接使用电脑自带的Windows系统进行部署(假设你用的Windows)
2.WSL+Ubuntu:使用Windows官方提供的系统组件,使用Windous来管理Liunx系统,换而言之,就是使用Liunx系统来进行模型微调
为什么要使用Ubuntu呢,原因如下:
- 1.LLaMA-Factory在Liunx的生态比Windows更好,LLaMA-Factory 官方文档本身是按常规 Linux / Python 环境来写安装流程的,而官方中文 README 也单独提到:Windows 下如果要开 QLoRA,需要额外装预编译的 bitsandbytes wheel,用Windows 方案能跑,但兼容性和折腾成本通常更高
- 2.安装超级简单,不需要装虚拟机,只需要一个命令行指令即可安装
- 3.WSL2 现在已经能比较正式地使用 NVIDIA CUDA进行GPU加速了,这不是早期那种“勉强能跑”的状态了,微软文档明确把 PyTorch/CUDA 训练工作流列进支持范围
读者可以自行选择,如果是想简单体验一下模型微调,跑最基础的推理或最轻量训练,那么只用Windows就够了,如果要真正开始做微调,笔者强烈推荐WSL+Ubuntu
安装WSL+Ubuntu,需科学上网:
PowerShell:wsl --install -d Ubuntu-22.04
安装完成后,使用Windows自带的搜索功能即可打开Ubuntu
打开后会让你输入账号和密码,依次填写即可
注意!WSL有两个版本,分别是WSL1和WSL2,WSL1是早期版本,只有勉强能用的水平,一定要使用WSL2!使用上面的命令默认使用的WSL2,使用该命令可以查看自己用的哪个版本wsl –list –verbose(查看VERSION这一列)
安装LLaMA-Factory
安装LLaMA-Factory本体
打开命令行或者PowerShell,拉取代码:
git clone https://gitee.com/hiyouga/LLaMA-Factory.git
完笔之后听说这个gitee库失效了,把gitee换成github即可,记得科学上网
配置虚拟环境
为了防止日后出现各种依赖报错,推荐给每一个项目都创建一个单独的虚拟环境
这里推荐使用UV这一个包管理工具
安装uv:
Windows:powershell -ExecutionPolicy Bypass -c "irm https://github.com/astral-sh/uv/releases/download/0.9.27/uv-installer.ps1 | iex"Liunx:pip install uv -i https://mirrors.aliyun.com/pypi/simple
创建虚拟环境:
uv venv finetune#这个finetune是虚拟环境的名字,可以自己改
进入虚拟环境,Windows:
finetune/Scripts/activate
Liunx:
source finetune/bin/activate
安装LLaMA-Factory依赖包
切换到安装目录:
cd LLaMA-Factory
下载依赖:
uv pip install -e ".[torch,metrics]" -i https://mirrors.aliyun.com/pypi/simple
这个过程大概是5-10分钟
验证一下GPU能不能用,应该输出Ture,显示False请查看疑难杂症
python -c "import torch;print(torch.cuda.is_available())"
疑难杂症
显示无法解析服务器的名称或地址怎么办
科学上网喵,科学上网谢谢喵
安装依赖 numpy==1.26.4 时失败怎么办
主要原因是缺少编译工具,去VScode官网下载安装 Visual Studio Build Tools,安装C++工具包即可
我怎么确认我有没有成功安装LLaMA-Factory
进入虚拟环境,输入:llamafactory-cli version 能显示版本号就成了
我怎么确认我有没有安装PyTorch
命令行输入:
python -c "import torch; print(torch.__version__)"
如果 PyTorch 已安装并且正常工作,会输出 PyTorch 的版本号,例如:1.13.1
如果未安装 PyTorch,会看到类似 ModuleNotFoundError: No module named 'torch' 的错误
验证GPU时显示False怎么办
GPU加速需要下载符合版本的英伟达CUDA和工具PyTorch
现这个问题的原因大致如下:
- 1、没有安装 CUDA:确保你的系统上安装了与你的 PyTorch 版本兼容的 CUDA 版本
- 2、没有安装 GPU 驱动:确保你的 GPU 驱动是最新的,并且与你的 CUDA 版本兼容
- 3、GPU 不支持:你的 GPU 可能不支持 CUDA 或者不被 PyTorch 支持
- 4、PyTorch 版本不兼容:你可能安装了一个不支持 CUDA 的 PyTorch 版本,确保你安装的是 CUDA 版本的 PyTorch
- 5、CUDA 运行时问题:CUDA 运行时可能存在问题,尝试重新安装或更新 CUDA
- 6、环境变量未设置:CUDA 相关的环境变量(如 CUDA_HOME、PATH 等)可能未正确设置,自行添加系统环境变量
- 7、系统权限问题:在某些情况下,权限问题可能会导致 CUDA 设备无法被访问
- 8、CUDA 版本与 GPU 不兼容:安装的 CUDA 版本可能与你的 GPU 不兼容
- 9、PyTorch 安装问题:PyTorch 安装可能存在问题,尝试重新安装
我的建议是安装CUDA13.0和PyTorch2.9.1,这俩是兼容的
检查CUDA版本:
nvcc --version
安装驱动后:
nvidia-smi #可以使用这条命令检查 GPU 是否被系统识别
下载 PyTorch 2.9.1 Windouws:
pip install torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 --index-url https://download.pytorch.org/whl/cu128在安装UV时Command ‘pip’ not found报错怎么办
在使用Ubuntu安装Python时不会自动装pip,装上就行
Ubuntu:
sudo apt update #更新列表,确保知道最新版本的 python3-pip 是否存在
sudo apt install python3-pip # 然后安装tyro 库报错怎么办
别用高版本Python,用3.10版本就行
第三部分,体验简单微调全过程
启动web界面
启动命令行,进入虚拟环境,输入即可:
llamafactory-cli webui
如果没出问题的话,稍后web面板会自动打开,如果没有自动打开就启动浏览器输入http://127.0.0.1:7860/
在language选项处选择zh切换成中文
模型下载源选择ModelScope,下模型不用科学上网
选择合适的模型
下载模型,笔者推荐魔搭网,这里有很多模型可以选择——传送石碑
在魔搭网上方选择模型库,你会看到非常非常多的模型,我们要怎么选择呢
1.个人推荐选择千问系列的模型,社区生态好,性能抗打,还有一点是因为qwen的命名方式很规范,举个例子:3.5qwen-7b-Thinking-base,即千问3.5—70亿参数—带思考功能—预训练模型,一目了然
顺便介绍一下常见的模型后缀,留个印象即可:
| 后缀名 | 含义 | 真正含义/口语 |
| Base | 仅经过大规模无监督预训练,未进行任何指令或对话微调 | 干不了事,要微调才能用 |
| Instruct | 指令微调是指使用大量 “指令-回答” 对数据对预训练基座模型进行进一步训练 | 已经微调过了,直接用(也可以继续微调) |
| Thinking | 模型经过了思维链增强训练,能够在输出最终答案之前,显式地展示推理过程 | 先思考,后回答 |
| Chat | 表示该模型经过了对话微调,更擅长多轮对话 | 天赋点聊天上了 |
| Vision / Audio / VLM | 是指模型能够同时处理和理解多种类型的数据(模态),例如文本、图像、音频、视频等 | 即多模态(能识图,视频等) |
| Lite / Tiny / Small / Nano | 表示模型参数量更小、层数更少,速度更快、资源占用低,但能力相应弱于标准版 | 轻量化版本 |
| Code | 在代码语料上额外预训练或微调,擅长代码生成、理解、调试 | 写代码很nb的模型 |
| GGUF / GPTQ / AWQ / FP16 / INT8 / INT4 | 深度学习模型中的权重和激活值从高精度,转换为低精度的压缩版本(量化模型) | 我显存不够 |
评论(0)
暂无评论